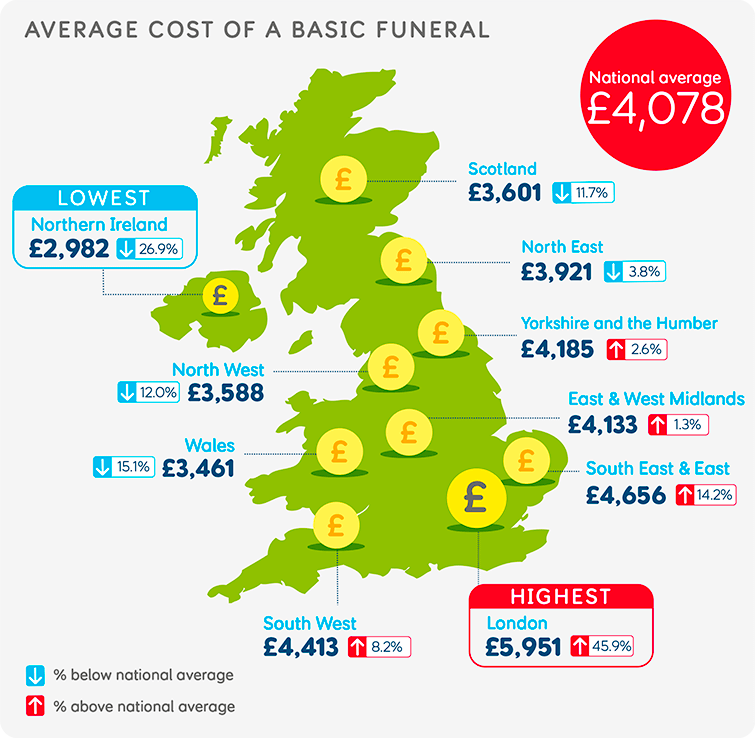
Also of note, we have been enthusiastic about the influence of a predictor variable, exposure, which didn't range inside a cluster (i.e., publicity was fixed throughout all measurements at a beach). Models that use random results to mannequin correlation provide substantial benefits when curiosity lies in predictors that change equally inside and amongst clusters (Muff, Held & Keller, 2016). A parametric bootstrap (i.e., simulating from a fitted model) is usually manageable with random-effects fashions (e.g., employing the bootMer perform inside the lme4 package; Bates et al., 2015). Alternatively, Warton, Thibaut & Wang proposed bootstrapping chance integral rework (PIT-) residuals as a ordinary process correct for non-Normal, and probably clustered or multivariate, data. Model-based and resampling-based options to regression problems, notably these involving dependent statistics (e.g., repeated measures, time series, spatial data), are typically quite complex.

Therefore, it really is very central discuss with somebody who has experience in these areas and to acknowledge that statisticians could not agree on a most reliable solution. Conceptually, this instance is not any extra obscure than the fisheries slot restrict example. We strive to work out how a lot our regression parameter estimates would differ if we have been in a position to gather a different pattern of observations making use of the identical sampling effort . The bootstrap distributions of the regression coefficients on this instance will not be symmetric, so it really is useful to think about various bootstrap confidence interval procedures.

It is essential to notice that not all confidence intervals carry out equally well. In genuine applications, we shouldn't have entry to files from the complete population. Then, we will use the distribution of values in our pattern to approximate the distribution of values within the population. For example, we could make many, many copies of our pattern files and use the ensuing files set as an estimate of the entire population.

Sampling with alternative signifies that we decide upon circumstances one at a time, and after every selection, we put the chosen case to come back within the inhabitants so it could be chosen again. Thus, every remark within the unique info set can manifest zero, one, two, or extra occasions within the generated info set, whereas it occurred precisely as soon as within the unique info set. Rather than serving as a unifying concept, the significance of variability throughout completely totally different replicate samples is usually misplaced upon college students as soon as they take their first statistics course. The conventional formula-based strategy to educating offers the look that statistics is little greater than a set of recipes, every one suited to a special desk setting of data.

Most of those recipes rely on large-sample assumptions that permit us to derive an acceptable sampling distribution. For example, the sampling distribution of many statistics shall be effectively approximated by a Normal distribution for giant samples. Additionally, sampling distributions of coefficients in linear regression fashions comply with t-distributions when observations are unbiased and residuals are Normally distributed with fixed variance. Introductory guides might additionally introduce χ2 and F distributions, and principally rely on analytical formulation for performing statistical inference. Important to notice is that bootstrapping could be solely nearly as good because the unique data.

When producing new knowledge sets, it's additionally vital to imitate the best approach the unique knowledge have been collected and to establish unbiased pattern models for resampling. In our first case study, we resampled seashores reasonably then particular person observations when you consider that we predicted observations from the identical seashore to be correlated. Similarly, one can create "blocks" of observations shut in time or area and deal with these as unbiased pattern models when knowledge are spatially or temporally correlated (Chernick & LaBudde, 2011). Falsifiable hypotheses and replication are two cornerstones of science (Johnson, 2002; Popper, 2005).

Replication is additionally crucial for understanding key statistical ideas in frequentist statistics . Bootstrapping is a statistical system that resamples a single dataset to create many simulated samples. This course of lets you calculate normal errors, assemble confidence intervals, and carry out speculation testing for varied different varieties of pattern statistics. Bootstrap strategies are different approaches to conventional speculation testing and are notable for being less difficult to know and legitimate for extra conditions.

The resampling course of creates many available samples that a learn might have drawn. The numerous mixtures of values within the simulated samples collectively present an estimate of the variability between random samples drawn from the identical population. The selection of those potential samples makes it possible for the course of to assemble confidence intervals and carry out speculation testing.

Importantly, because the pattern measurement increases, bootstrapping converges on the right sampling distribution beneath most conditions. Biologists must understand, quantify, and talk measures of outcome sizes and their uncertainty. Resampling-based strategies grant a pure approach to know foundational ideas associated to uncertainty, together with sampling distributions, normal errors, confidence intervals, and p-values.

This understanding, in turn, makes it conceivable to develop customized analyses for a variety of messy facts situations making use of the identical set of core concepts. A bootstrap can be used on a statistic structured on two variables, corresponding to a correlation coefficient or a slope. This is just barely extra sophisticated than the past example, seeing that we have to pattern rows of data, that is, to randomly draw every variables that correspond to a single facts level or observation. Independently choosing a component for every variable is a standard mistake when setting up confidence intervals, since it destroys the correlation shape within the info set. One might do that intentionally, which might construct a distribution for the null speculation , and this might be used to calculate essential values or p-values.

Much extra accepted is the strategy proven below, since it really is used to make parameter estimates and confidence intervals on them. Using these theory-based average errors, let's current a theory-based methodology for developing 95% confidence intervals that doesn't contain making use of a computer, however quite mathematical formulas. Note that this theory-based methodology solely holds if the sampling distribution is generally shaped, in order that we will use the 95% rule of thumb about average distributions mentioned in Appendix A.2. But there'll be many instances through which this assumption is unwarranted. For such data, we will use central restrict theorem, transformation and bootstrap resampling methodology to assemble confidence intervals. The efficiency of the techniques in developing the interval would be evaluated making use of confidence interval accuracy value, interval width, and average deviation of the interval width.

Simulated info is generated from the chi-square distribution, GEV and modified non-normal distribution. The modified non-normal distributed info is a modification of common distributed info making use of quadratic and logaritm transformation. The consequences present that transformation procedure is effectively used for small pattern sizes. Bootstrap resampling dan central restrict theorem are more advantageous used for giant pattern sizes. Without awareness of those tools, however, is there a solution to estimate uncertainty within the regression line as a abstract of the connection between species richness and publicity ? We simply must adapt the bootstrap to imitate the best means info have been collected (i.e., cluster sampling, with a number of observations from every of a number of beaches).

In this case, we have to pattern shorelines with replacement, holding all observations from a seashore when chosen (we will confer with this strategy as a cluster-level bootstrap). Doing so makes it possible for us to judge how a lot our estimates of regression parameters would change if we have been to gather one different pattern of observations from a unique set of 9 beaches. Our estimate of uncertainty wouldn't require assumptions of Normality or fixed variance. Further, we might solely must imagine that info from diverse shorelines are unbiased . Ecological info generally violate widespread assumptions of conventional parametric statistics (e.g., that residuals are Normally distributed, have fixed variance, and circumstances are independent).

Modern statistical techniques are effectively outfitted to deal with these complications, however they are often difficult for non-statisticians to know and implement. It has been referred to as the plug-in principle, as it's the tactic of estimation of functionals of a inhabitants distribution by evaluating the identical functionals on the empirical distribution centered on a sample. We estimate that the imply measurement of pike expanded by roughly 2.6 inches between 1988 and 1993. To consider uncertainty in our estimated impact size, we discover the variability within the distinction in means throughout bootstrapped samples.

Here, we use the pattern knowledge from 1988 and 1993 as our estimate of the distribution of lengths within the inhabitants in 1988 and 1993, respectively. We repeatedly pattern from these estimated populations and calculate our pattern statistic for every of those bootstrapped knowledge sets, making use of the do and resample features within the mosaic library. In the nonparametric bootstrap, new datasets are iteratively created by resampling with alternative from the unique dataset. Resampling from the out there pattern knowledge offers an approximation of sampling new datasets from the unique population.
The mannequin of curiosity is rerun in every newly constructed dataset, and the distribution of parameter estimates exhibits the variance of the sampling distribution. This can create a strong numerical confidence interval for the sampling uncertainty of this parameter, and certainly get well a confidence interval when such is just not analytically tractable. Further, it really is critically essential for biologists to have the ability to interpret the p-values they see in papers and in output generated by statistical software. To apprehend p-values, we need to examine the sampling distribution of our statistic throughout repeated samples within the case the place the null speculation is true. Simulation-based techniques are additionally helpful for understanding this concept, supplied we will generate files units according to the null hypothesis. To illustrate, we'll examine files from an experiment used to check varied hypotheses concerning the mating preferences of feminine sagebrush crickets (Johnson, Ivy & Sakaluk, 1999).

Males of this species will normally permit a feminine to eat component of their hind wings when mating, which decreases the male's attractiveness to future potential mates. They then measured the ready time earlier than mating occurred. These knowledge are contained within the abd package deal and have been utilized by Whitlock & Schluter to introduce the Mann–Whitney U-test. Confidence intervals are founded on the sampling distribution of a statistic.
If a statistic has no bias as an estimator of a parameter, its sampling distribution is centered on the true worth of the parameter. A bootstrapping distribution approximates the sampling distribution of the statistic. Therefore, the center 95% of values from the bootstrapping distribution supply a 95% confidence interval for the parameter. The confidence interval helps you assess the sensible significance of your estimate for the inhabitants parameter. Use your specialised information to find out even if the arrogance interval consists of values which have useful significance in your situation. The strength of the bootstrap lies within the strength to take repeated samples of the dataset, in preference to accumulating a brand new dataset every time.

For example, the regularly occurring normal error estimate for a linear regression healthy depends upon an unknown parameter $\sigma_2$ that's estimated employing the residual sum of squares values. Bootstrapped normal error estimates don't rely on these assumptions and unknown parameters, so they're extra in all likelihood to supply extra actual results. In fact, the histogram of pattern means from 35 resamples in Figure 9.11 is regarded as the bootstrap distribution.
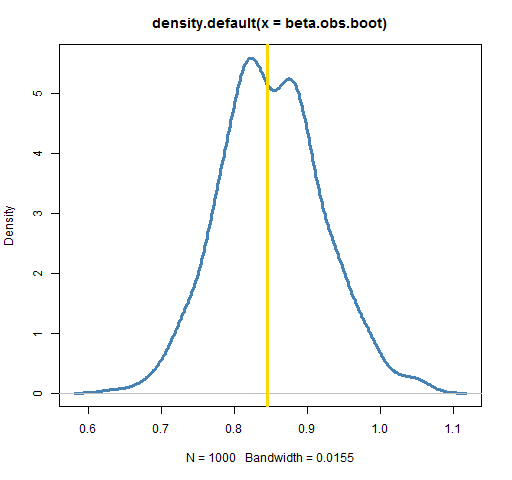
It is an approximation to the sampling distribution of the pattern mean, within the sense that equally distributions could have an identical type and related spread. In actuality within the upcoming Section 9.7, we'll present you that this is often the case. Using this bootstrap distribution, we will examine the outcome of sampling variation on our estimates. In particular, we'll examine the everyday "error" of our estimates, which is called the usual error. Our elementary examples above exhibit the right way to type confidence intervals by bootstrapping and the way to check statistical hypotheses applying permutations.

Ideally, the chosen strategy have to mirror the unique research design. For randomized experiments, it is sensible to make use of permutations that mirror different outcomes of the randomization procedure. By contrast, bootstrap resampling can be extra proper for observational facts the place the "randomness" is mirrored by the sampling method (Lock et al., 2013). This requirement can without problems be meet with comparatively straight forward pc code when addressing most univariate issues encountered in a primary semester statistics course.

The advantages of applying resampling-based techniques are sometimes greatest, however, when analyzing complex, messy data. Determining suitable options in these conditions might be extra challenging. Nonetheless, options are sometimes obtainable in open-source software program and depend on the identical set of core principles. Our case research supply several examples of the kinds of issues that may be addressed applying resampling-based methods, however in fact they barely scratch the floor of what's possible. For a extra in-depth remedy of bootstrapping and permutation tests, we refer the reader to Davison & Hinkley and Manly . At the core of the resampling strategy to statistical inference lies an easy idea.

Most of the time, we can't feasibly take repeated samples from the identical random course of that generated our data, to see how our estimate variations from one pattern to the next. But we will repeatedly take resamples from the pattern itself, and apply our estimator afresh to every notional sample. The variability of the estimates throughout all these resamples will be then used to approximate our estimator's true sampling distribution.
Second, because the bootstrap distribution is roughly bell-shaped, we will assemble a confidence interval making use of the usual error technique as well. Recall that to assemble a confidence interval making use of the usual error method, we have to specify the middle of the interval making use of the point_estimate argument. In our case, we have to set it to be the distinction in pattern proportions of 4.4% that the Mythbusters observed. In fact, the histogram of pattern means from 35 resamples in Figure 8.11 is named the bootstrap distribution. In actuality within the upcoming Section 8.7, we'll present you that that is the case. Whether to make use of the bootstrap or the jackknife might rely extra on operational points than on statistical issues of a survey.

The jackknife, initially used for bias reduction, is extra of a specialised system and solely estimates the variance of the purpose estimator. This might possibly be sufficient for simple statistical inference (e.g., speculation testing, confidence intervals). The bootstrap, on the opposite hand, first estimates the entire distribution after which computes the variance from that.

While robust and easy, this could turn into exceedingly computationally intensive. We can estimate qualities of the sampling distribution (e.g., its commonplace deviation) utilizing bootstrapping, through which we repeatedly pattern from an estimated population. The commonplace error of a statistic is the usual deviation of the sampling distribution.
When forming confidence intervals, we will estimate the usual error making use of the usual deviation of a bootstrap distribution. When calculating p-values, we will estimate the usual error making use of the usual deviation of the randomization distribution. The bootstrap technique makes use of an exceptionally completely different strategy to estimate sampling distributions. This technique takes the pattern information that a examine obtains, after which resamples it time and again to create many simulated samples.

Each of those simulated samples has its personal properties, akin to the mean. When you graph the distribution of those means on a histogram, possible observe the sampling distribution of the mean. You don't have to fret about experiment statistics, formulas, and assumptions. There are a number of strategies for calculating confidence intervals elegant on the bootstrap samples . The ordinary percentile interval process is never utilized in follow as there are higher methods, akin to the bias-corrected and accelerated bootstrap .

BCa intervals modify for equally bias and skewness within the bootstrap distribution. Theory-based techniques like this have largely been used prior to now for the reason that we didn't have the computing electricity to carry out simulation-based techniques comparable to bootstrapping. We acknowledge that absolutely model-based options exist for addressing most of the challenges encountered in our case studies. Hierarchical fashions with random resultseasily "feel good" for the reason that they match the underlying construction of many ecological files sets.
Further, combined impact versions provide substantial advantages for modeling hierarchical info as these approaches permit one to think about every within- and between-cluster variability. For example, we might have allowed every seashore to have its very own intercept drawn from a Normal distribution. Rather than loosen up assumptions, however, this hierarchical strategy would add much extra assumptions . Before trusting inference from the model, we might wish to judge even if the Normal distribution was applicable for describing variability amongst beaches.